
源代码 github: https://github.com/VonSdite/SchoolRank
数据来源
中国学位与研究生教育信息网 => http://www.cdgdc.edu.cn/xwyyjsjyxx/xkpgjg/
数据是全国第四轮学科评估结果,该数据于2017年12月28日发布
目的
做这个脚本的缘由,
- 因为身边总有同学要讨论哪个高校哪个高校比较优秀, 讲道理, 要看哪个高校优秀, 还是要具体到高校的具体专业, 口说无凭, 数据说话
- 可以方便大家知道某个高校的强势在哪里
脚本介绍
需要的第三方库
- wordcloud:
pip install wordcloud- pandas:
pip install pandas- numpy:
pip install numpy- matplotlib:
pip install matplotlib- pillow:
pip install pillow- requests:
pip install requests- BeautifulSoup:
pip install beautifulsoup4
show.py
展示学校的评估结果
使用
- 在该项目目录下打开终端
- 键入
show.py [学校名]即可
比如,show.py 暨南大学
如果想比较多个学校之间的评估结果, 可以这样操作show.py 西安交通大学 中山大学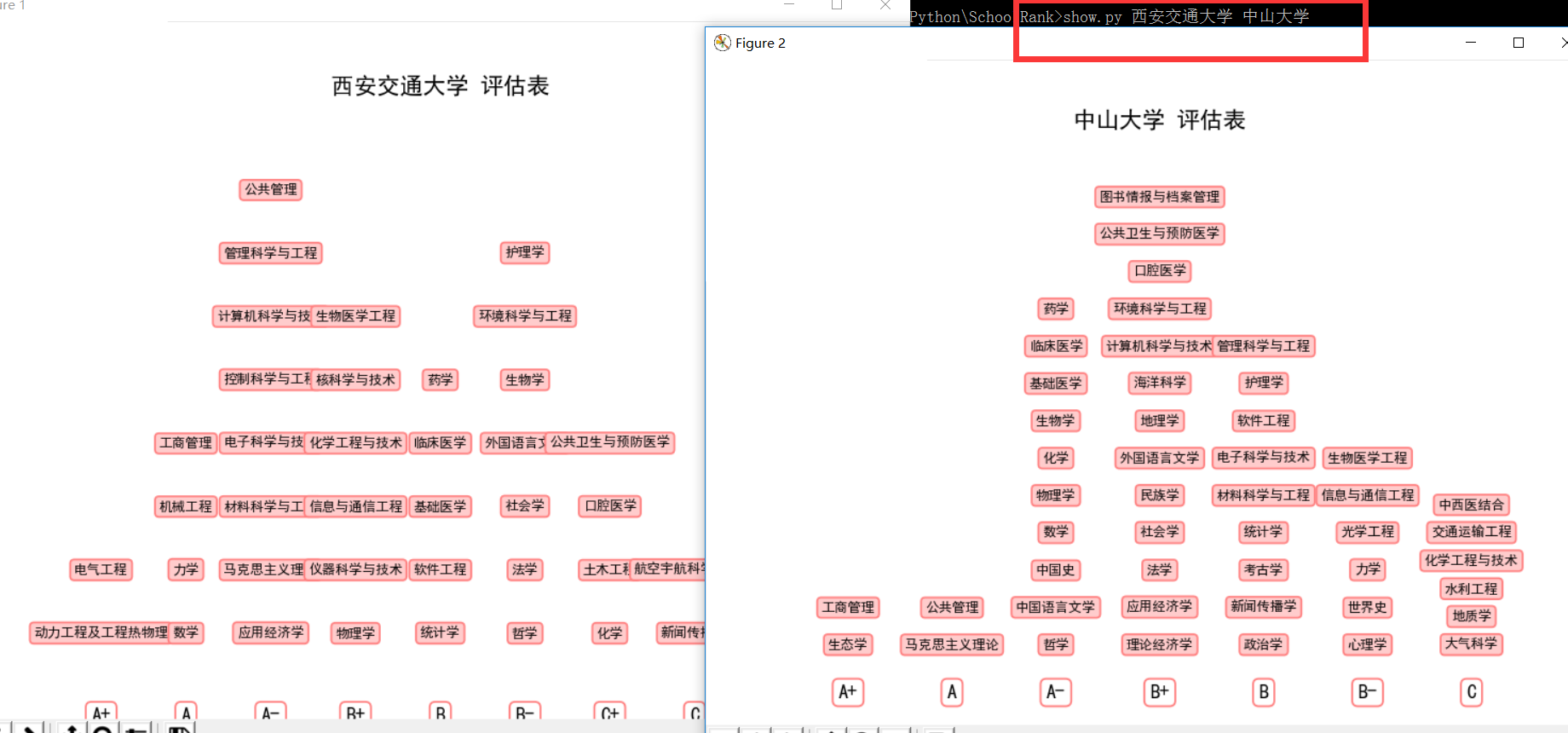
GetSomeData/GetSchoolRank.py
用于获取高校评估的脚本
使用爬虫来获取 全国第四轮学科评估结果, 将数据保存为了 schoolRank.xlsx, 保存为.xlsx文件是为了方便使用excel进行操作(也可以自己保存为.csv文件来进行数据处理, 代码中已注释)
schoolRank.xlsx数据展示
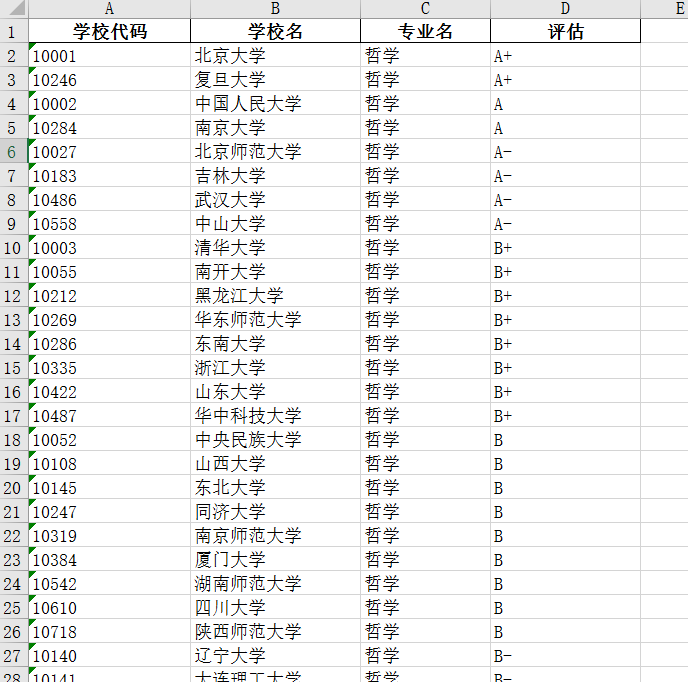
可以通过excel来筛选查看数据(比自己造轮子来的方便多了)
比如, 查看 暨南大学的评估结果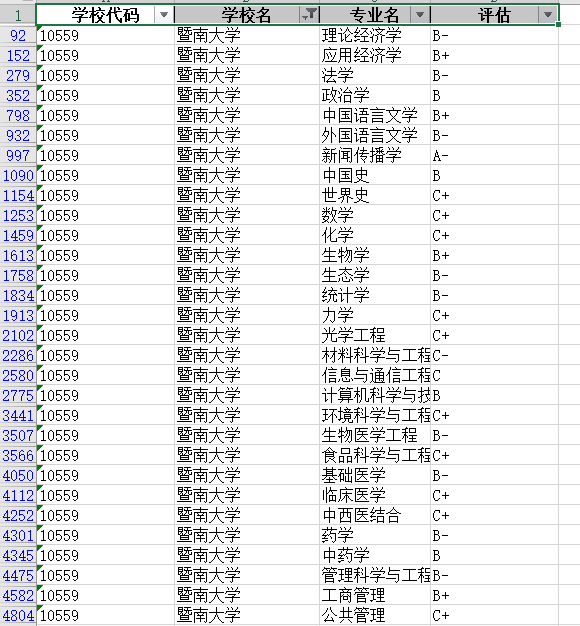
GetSomeData/AssessmentAnalysis.py
用于统计每个学校得到各个评估的次数
通过pandas简易处理下数据, 将数据保存为了 schoolRank.xlsx, 保存为.xlsx文件是为了方便使用excel进行操作(也可以自己保存为.csv文件来进行数据处理, 代码中已注释)
schoolAssementCount.xlsx数据展示
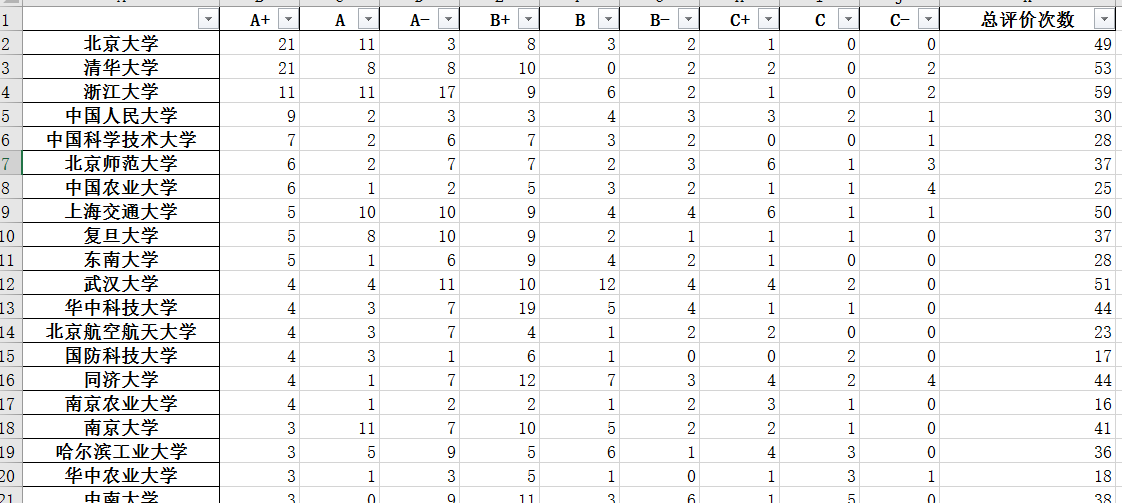
同样可以通过excel来筛选查看数据
GetSomeData/GetWordCloud.py
以schoolRank.xlsx中的学校名来作词云, 实际就是按学校参加评估的总次数来画词云
该项目生成的词云如下:
注意
注意1wordcloud 不支持显示中文, 可以通过如下修改来支持中文:
- 进入
python根目录, 然后进入Lib\site-packages\wordcloud - 进入
C:\Windows\Fonts目录下, 拷贝一个中文字库, 如华文新魏, 将其复制粘贴到Lib\site-packages\wordcloud目录下

- 打开
Lib\site-packages\wordcloud目录下wordcloud.py, 找到如下这行代码
将代码改为对应拷入进来的字库名字, 如华文新魏的字库名字为STXINWEI.TTF
- 至此解决中文乱码问题
注意2wordcloud的WordCloud类中的generate方法是先对传进去的文字进行分词, 但是对中文的分词效果不太好, 建议先自己计算词频, 存放到字典中, 然后使用generate_from_frequencies来生成词云
1 | from wordcloud import WordCloud |


