timeit
1 | import timeit |
timeit只输出被测试代码的总运行时间, 单位为秒, 没有详细的统计.
timeit的详细介绍点这里
profile / cProfile
profile: 纯Python实现的性能测试模块, 接口和cProfile一样cProfile: c语言实现的性能测试模块, 接口和profile一样
1 | import profile |
1 | import cProfile |
解释
1 | import cProfile |
- 上述运行表明有199个函数被调用, 其中有194个原生调用(即不涉及递归调用)
- 总共运行时间 0.000 seconds
- 结果按标准名称进行排序
- 列表中
ncalls表示函数调用的次数(有两个数值表示有递归调用, 总调用次数/原生调用次数)tottime是函数内部调用时间(不包括他自己调用的其他函数的时间)- 第一个
percall=tottime/ncalls cumtime累积调用时间, 它包含了自己内部调用函数的时间- 第二个
percall=cumtime/ncalls - 最后一列: 文件名, 行号, 函数名
line_profiler
line_profiler可以统计每行代码的执行次数和执行时间等, 时间单位为微秒。
安装
1 | pip install line_profiler |
安装之后, python 下会多一个kernprof.py
使用
在需要测试的函数加上
@profile装饰, 这里我们测试代码test.py运行命令行:
kernprof -l -v test.py
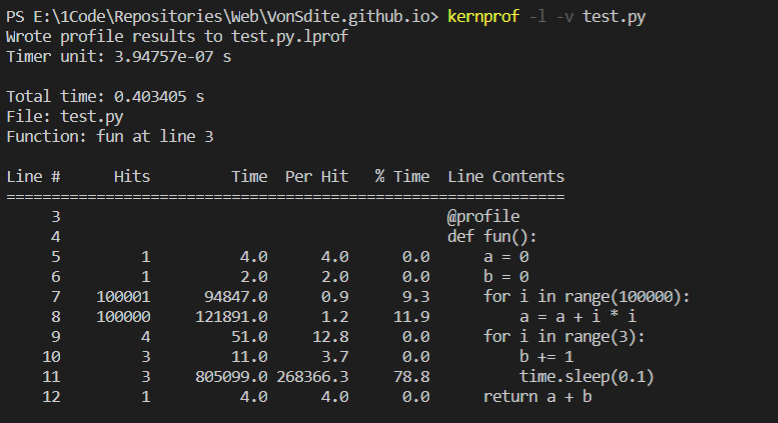
Total Time: 测试代码的总运行时间File: 测试的代码名Function: 测试的函数所在的行Line #: 表示代码的行号Hits: 表示每行代码运行的次数Time: 每行代码运行的总时间, 时间单位为微秒Per Hits: 每行代码运行一次的时间, 时间单位为微秒% Time: 每行代码运行时间的百分比
1 | import time |
memory_profiler
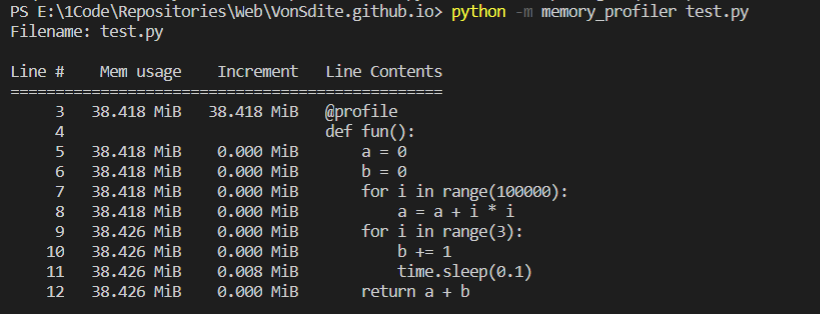
memory_profiler工具可以统计每行代码占用的内存大小。
安装
1 | pip install memory_profiler |
使用
在需要测试的函数加上
@profile装饰执行命令:
python -m memory_profiler test.py
Pycharm图形化性能测试工具
PyCharm提供了性能分析工具Run-> Profile, 如下图所示。利用Profile工具可以对代码进行性能分析, 找出瓶颈所在
使用
测试代码见下文, 一共有5个函数, 每个函数都调用了time.sleep进行延时
点击Run-> Profile开始测试, 代码运行结束后会生成一栏测试结果,
测试结果由两部分构成, Statistics(性能统计)和Call Graph(调用关系图)
Statistics(性能统计)

性能统计界面由Name、Call Count、Time(ms)、Own Time(ms) 4列组成一个表格。
Name显示被调用的模块或者函数Call Count显示被调用的次数;Time(ms)显示运行时间和时间百分比, 时间单位为毫秒(ms), 包含自己内部调用函数的时间Own Time(ms)显示运行时间和时间百分比, 时间单位为毫秒(ms), 不包含自己内部调用函数的时间
小技巧
- 点击表头上的小三角可以升序或降序排列表格。
- 在
Name这一个列中双击某一行可以跳转到对应的代码。
Call Graph(调用关系图)
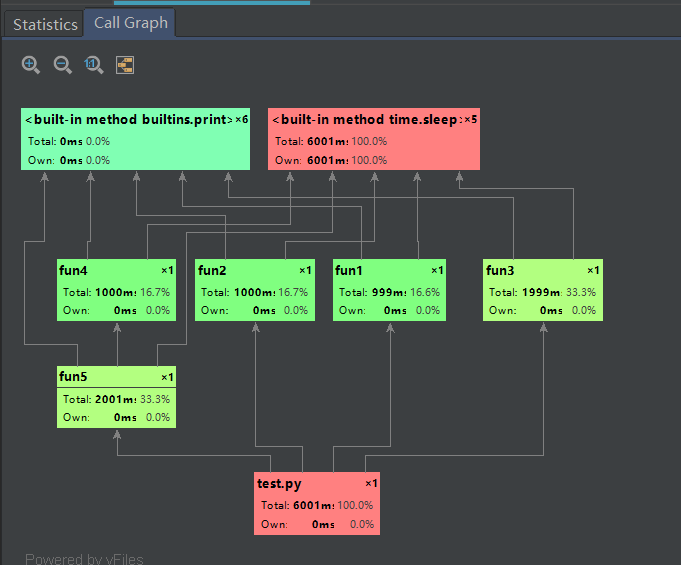
Call Graph(调用(系图), 包含了自己内部调用函数的时间界面直观展示了各函数直接的调用关系、运行时间和时间百分比。
解释
箭头表示调用关系, 由调用者指向被调用者;
矩形的左上角显示模块或者函数的名称, 右上角显示被调用的次数;
矩形中间显示运行时间和时间百分比;
矩形的颜色表示运行时间或者时间百分比大小的趋势: 红色 > 黄绿色 > 绿色, 比如由图可以看出fun3的矩形为黄绿色, fun1为绿色, 所有fun3运行时间比fun1长。
从图中可以看出
test.py直接调用了fun3、fun1、fun2和fun5函数; fun5函数直接调用了fun4函数; fun1、fun2、fun3、fun4和fun5都直接调用了print以及sleep函数; 整个测试代码运行的总时间为6001ms, 其中fun3的运行时间为1999ms, 所占的时间百分比为33.3%, 也就是 1999ms / 6006ms = 33.3%。
1 | # -*- coding: utf-8 -*- |
objgraph
objgraph是一个实用模块, 可以列出当前内存中存在的对象, 可用于定位内存泄露
推荐文章: http://python.jobbole.com/88827/
详情还是谷歌或百度一下, 日后看了再补充

