前言
在训练VOC数据集时, 总是出现Cannot load image的问题, 既有乱码也有打不开的问题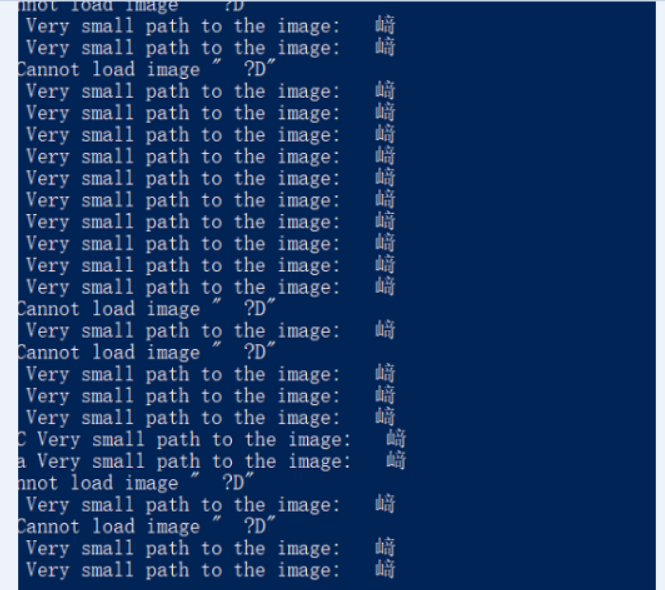
解决办法
最终解决办法
找了很多网上的解决办法, 无非都是改最后的换行符为Unix的LR换行符, 但对于我来说还是没能成功。
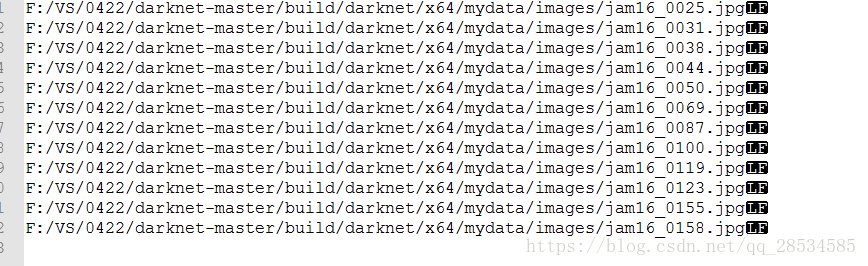
问题出现于train.txt文件上, 我重新新建一个txt文件(切记不要用记事本打开, 用sublime、vscode、notepad++等打开),
将train.txt的内容拷贝到新的txt文件中, 删除旧的train.txt, 重命名新的txt的文件为train.txt, 解决问题
所以问题出在哪?
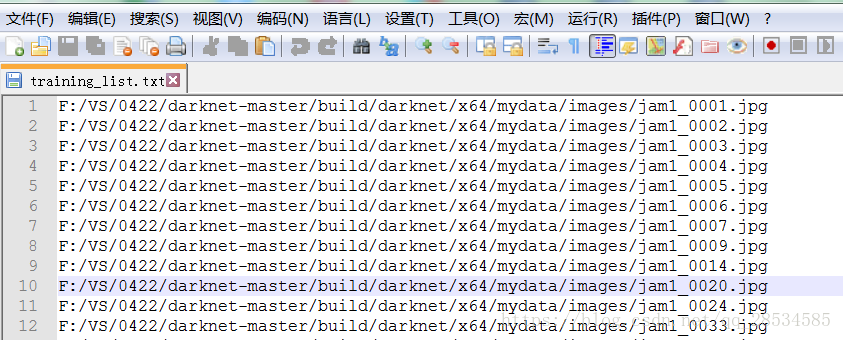
我最开始生成train.txt的思路和darknet思路一致, 如下
1 | cat 2007_train.txt > train.txt |
darknet上的是
1 | cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt |
windows的cmd是没有cat命令的, 但是powershell有cat命令, 但是直接用darknet上的命令会失败, 拆行写追加即可生成train.txt
所以问题在这个txt身上, 尝试过网上改换行符为Unix的LR换行符, 很不幸的失败了。
但转念考虑, 这个txt可能和windows的记事本有关(我没有用记事本打开过train.txt)。
而在windows平台下, 使用系统的记事本以UTF-8编码格式存储一个文本文件, 由于Microsoft开发记事本的团队使用了一个非常怪异的行为来保存UTF-8编码的文件, 它们自作聪明地在每个文件开头添加了0xefbbbf(十六进制)的字符, 所以这个问题可能出在了这个十六进制字符上
所以解决办法
- 如上, 新建一个
txt, 不要使用记事本打开, 把原来的数据拷贝过来即可解决- 用如下的
py代码来生成train.txt, 当然这里是指 VOC数据集, 自己按自己情况来写
1 | file = ['2007_train.txt', '2007_val.txt', '2012_train.txt', '2012_val.txt'] |
网上常见解决办法
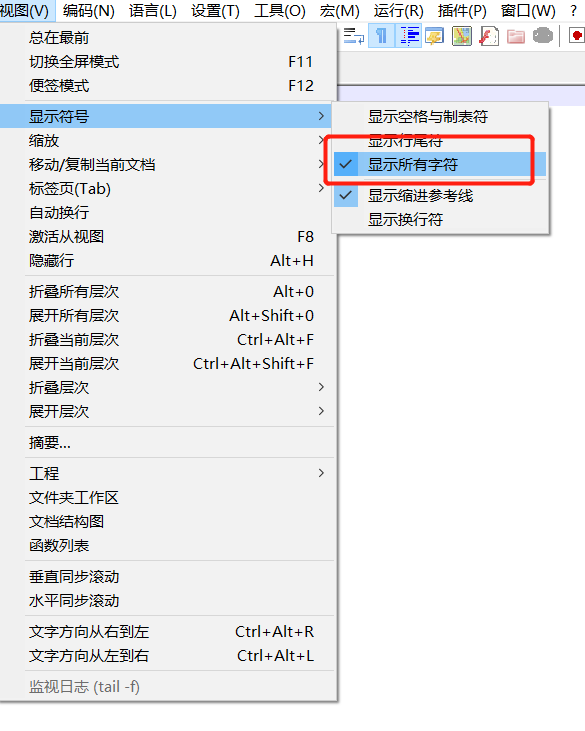
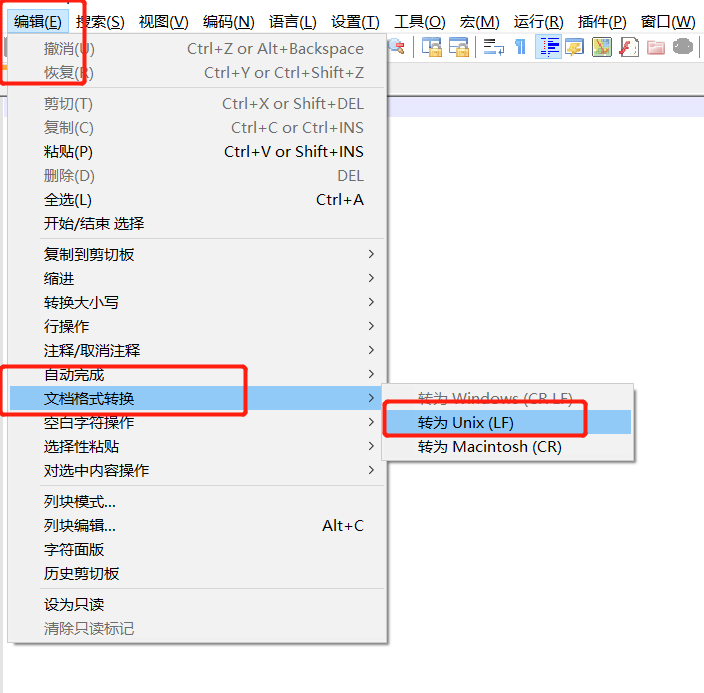
解决方法: 使用Notepad++
(1) 视图 => 显示符号 => 显示所有符号;
(2) 编辑 => 档案格式转换 => 转换为UNIX格式;
确保最后一行有且仅有一个LF